Stop Using A/B Tests to Pick Winners. 6 Steps to Make Better Product Decisions
Your analyst might hate me for this one. Most teams run A/B tests to find the “better” version. Here's why that mindset fails — and how I rewired mine after a few painful lessons

I used to think the point of an A/B test was simple:
👉 Run the experiment. Find the winner. Roll it out.
Back when I worked in marketing, I loved this. We ran constant split tests in email campaigns, ads, landing pages.
The volume felt like progress. More tests → more learnings → more growth.
But it was a lie.
The Seduction of “More Tests”
When I moved into product, I tried to keep the same approach.
I read case studies from Booking.com.
I devoured Netflix’s experimentation blog.
I thought “this is what real product teams do.” So I tried to A/B test everything.
But reality kicked in:
Low traffic made tests inconclusive
Results were noisy or unclear
We ran tons of tests with no business impact
I even wrote about why chasing more tests is a trap click the link below.

My Turning Point
I doubled down on learning. I read about sequential sampling, Bayesian stats, faster proxies to shorten test cycles.
But then I had to stop myself.
I looked back at months of experiment logs.
All the “wins” didn’t even cover the cost of the team.
One example:
We ran an A/B test on our pricing page. It boosted GMV in that cohort 10x.
Sounds huge, right?
But our total GMV was over $100M a year. That pricing tweak moved the needle by less than a rounding error.
Same story for email tests. We’d get 10pp lifts in click-through, but it translated to an extra $1,000 here and there.
For a business our size, it was noise.
That’s when I paid for my first Reforge subscription. I went through Elena Verna’s experimentation course.
Game changer. It didn’t all land immediately. I did it three times.
But I walked away with a core truth:
The job of an experiment isn’t to pick the winner. It’s to reduce risk.
The First Change I Made
We started by rewriting every hypothesis.
Old way: If we change the onboarding screens, conversion to trial will increase by 8%.
Sounded great in theory. But it led to:
Debates over too many changes in one variant
Results that were hard to interpret (was +6% good enough?)
No understanding of why conversion improved

New way: If we make this change, it will solve the user's problem or address their objection. We'll know we're right if we see the change in metric X.
That single change forced us to:
Pinpoint user problems
Ditch tests that didn’t solve anything
Generate learnings we could reuse elsewhere
We reduced testing time by choosing metrics that best explained user behaviour change instead of top-line business metrics like paid conversion
The Second Big Shift
We stopped chasing quantity.
A/B tests are expensive.
They don’t replace research or design. They add cost: setup, monitoring, analysis, decision-making. And you’re losing money during the test if only half of users see the better experience.
So we started scoring ideas with a Value & Risk quadrant:
Value = impact on the core metric
Risk = cost to develop + time to test + market/user uncertainty

We used this to categorise ideas:
No-Brainers (High Value, Low Risk) — ship them. A/B testing them is actually a cost.
Low-Hanging Fruit — small wins. Worth testing only if you have huge traffic.
Big Bets — high risk, high reward. A/B is just one tool, and often not the best.
Duds — Low Value, High Risk. Don’t touch them.
If you want to get good at this, read Annie Duke’s Thinking in Bets.
Because a statistically significant test still has ~5% chance of being wrong.
An experiment is just a tool to reduce the risk of making the wrong call. It doesn’t eliminate it.
The Updated Framework
Here’s how I approach testing now:
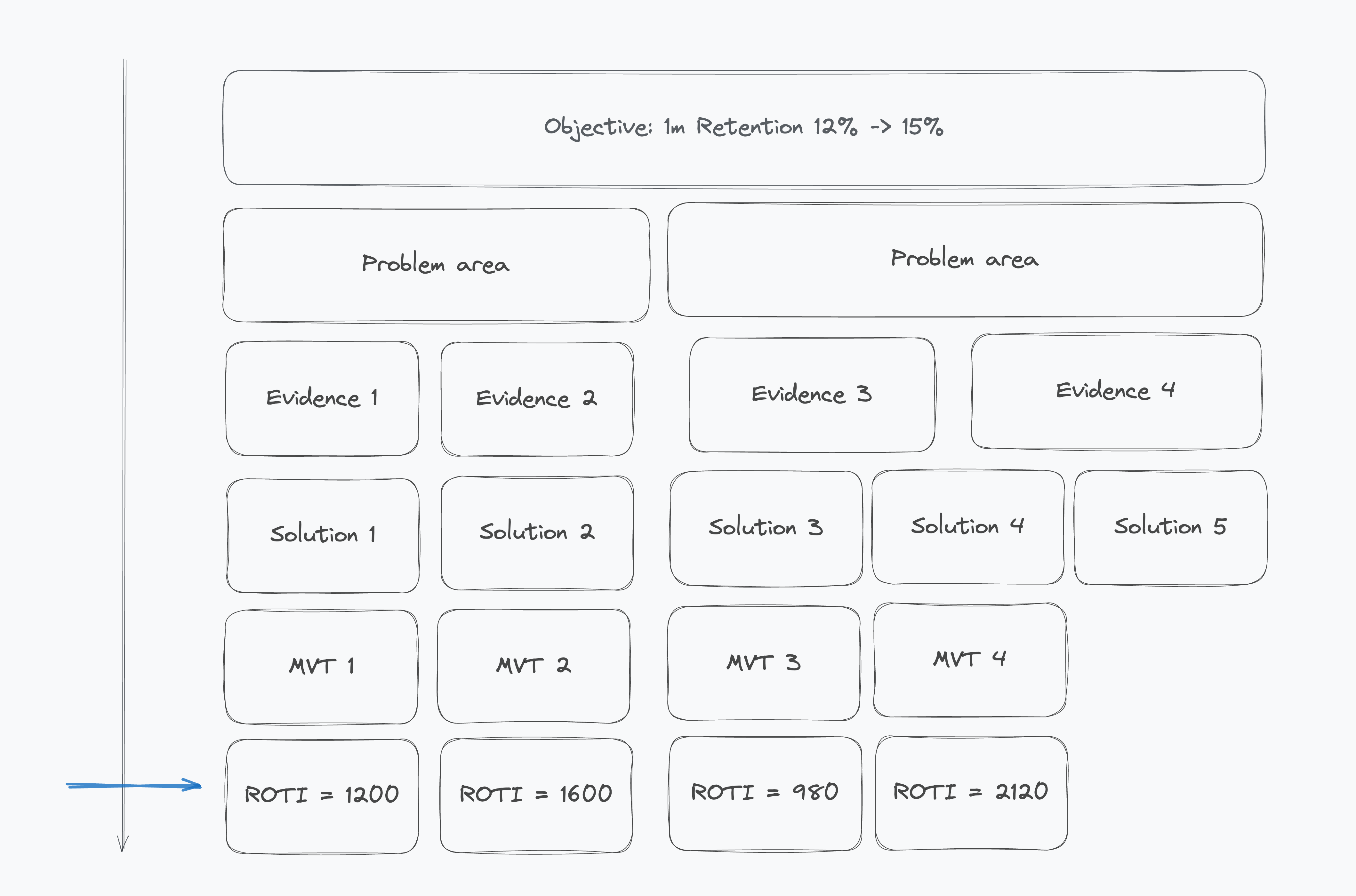
1️⃣ Define the Objective
Be clear on the business goal. Remember, this is about keeping focus on the biggest lever for your growth model. If you can’t say what impact you want this quarter, don’t bother testing.

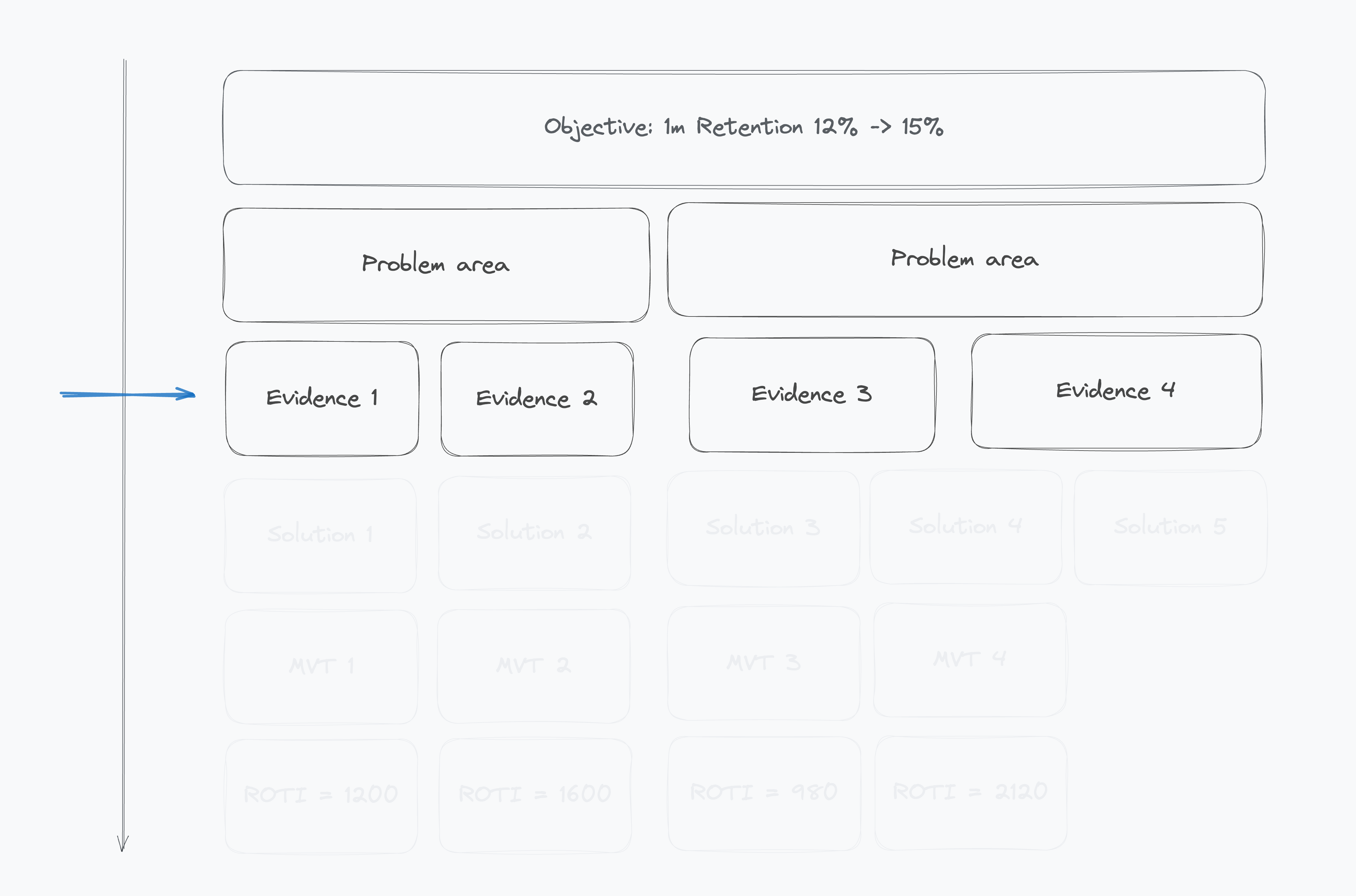
2️⃣ Map the Gap
Break down the metric into drivers. Segment the problem. Where exactly are you losing users? Why?
Remember to decompose your goal into its drivers and highlight the top 2-3 key problems you'll target with solutions next.

3️⃣ Prove the Problem Exists
Quantify the drop-off. Attach real user feedback. Avoid solving made-up problems. The goal of this step is to eliminate what you thought was a problem but isn't, and to choose the single biggest problem where solving it will give you the biggest lift.
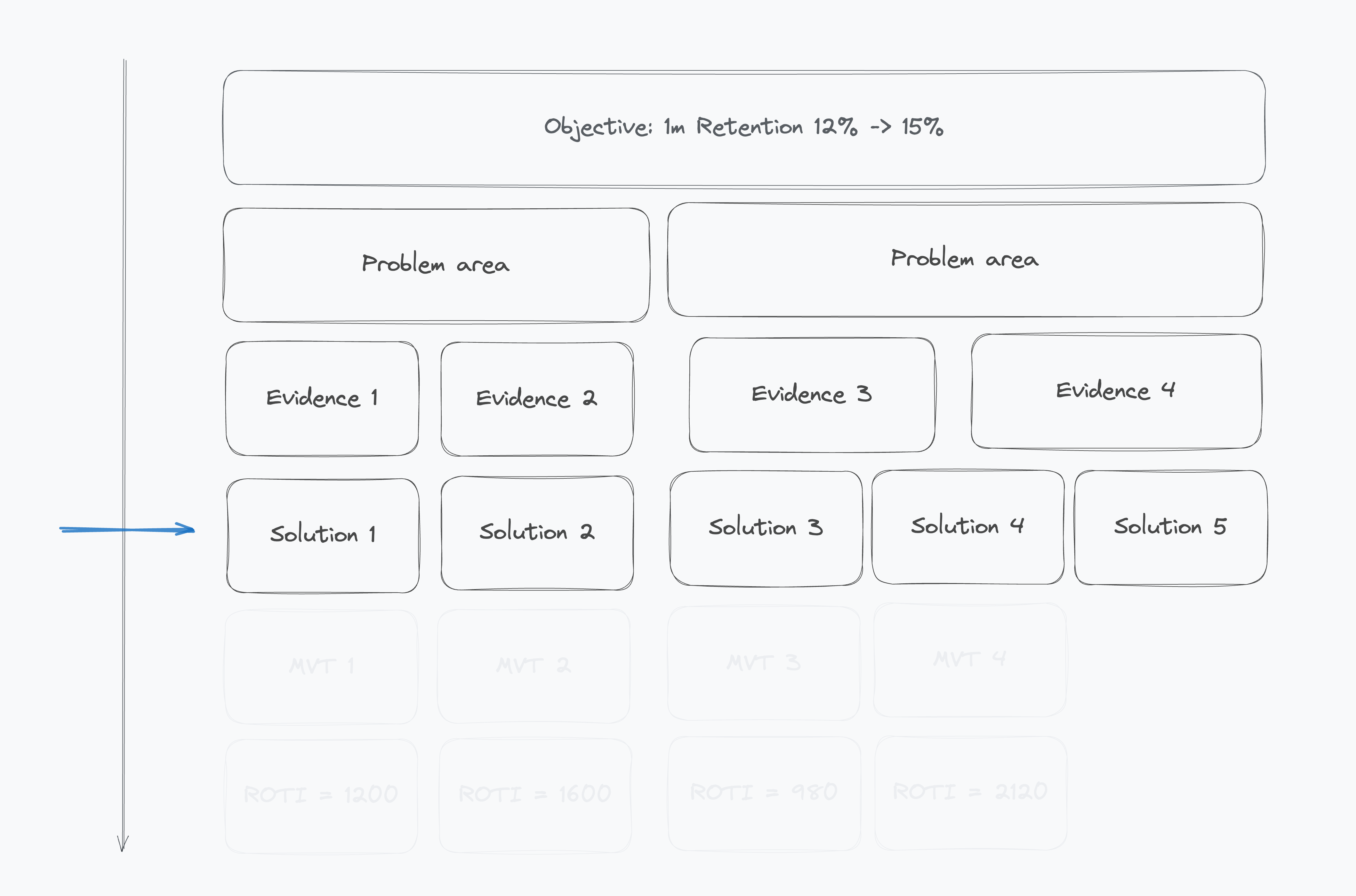
4️⃣ Ideate Solutions
For each problem, come up with 2–3 ways to fix it. Prioritise using the Value & Risk quadrant (see the quadrant description above for details).
Depending on the maturity of your team, I use different portfolios of tests: proportions of low-hanging, big bets, etc. But the general rule is if you end up with a No-brainer here, focus on shipping it quickly. If you're right, you might hit your quarterly goal just with that. Keep using the table for Low-Hanging & Big Bets.
5️⃣ Choose the Right Test
Think beyond A/B:
Clickbait prototype
Concierge tests
Fake doors
Wizard of Oz
Pre-orders
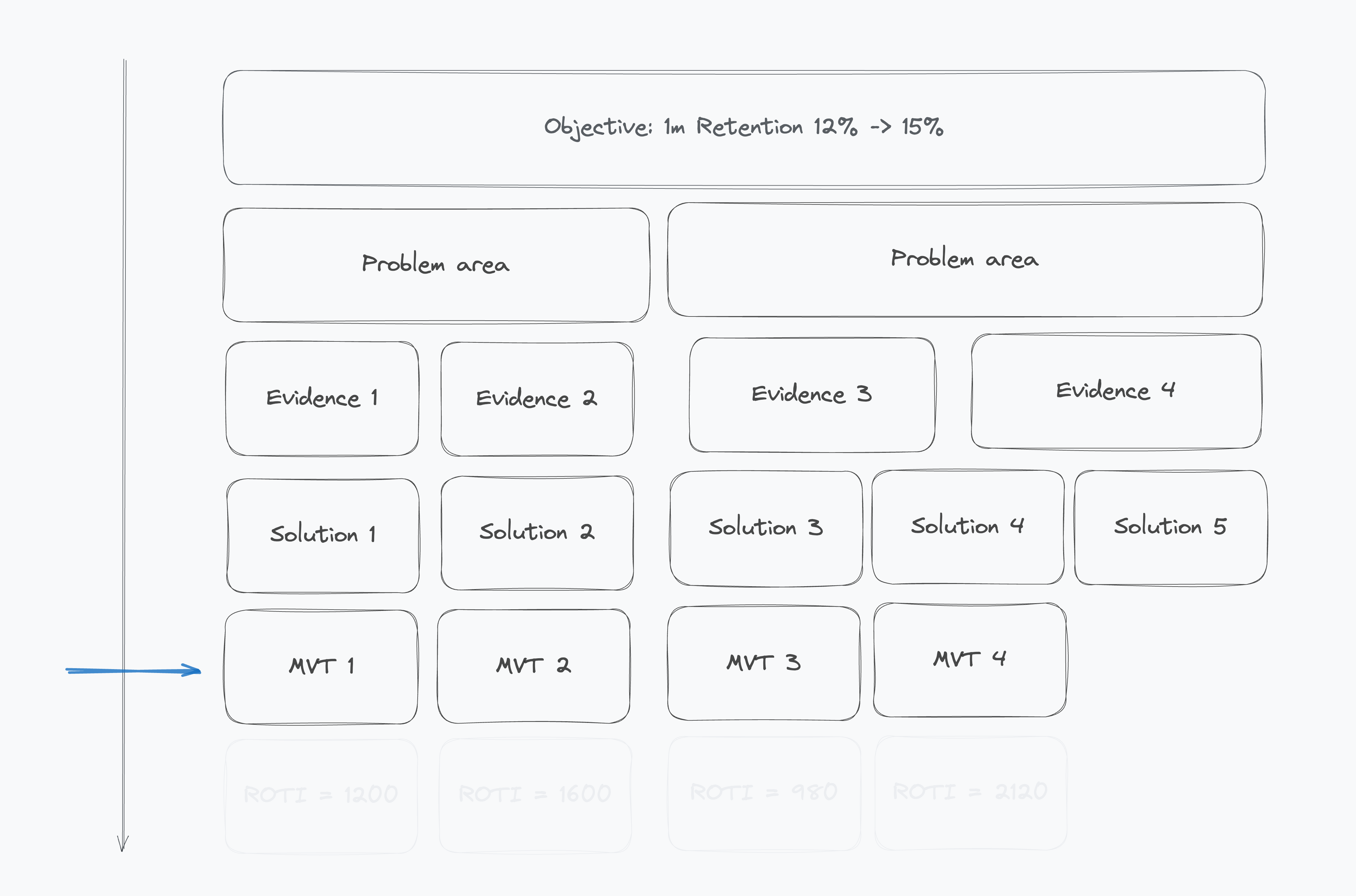
A/B is just one option.
If you want another 72 testing methods with instructions – just ask me on LinkedIn
6️⃣ Prioritise with ROTI (Return on Time Invested)
\(Impact * Confidence / Resources (in weeks)\)
Impact: model the potential business value. Use the same method across teams.
Confidence: ground it in data — past tests, user logs, qualitative insights.
75% – you have a result from a past A/B test, similar launch, or something already tested and learned from.
50% – there's qualitative evidence or logs suggesting you're likely right.
25% – raw idea, spotted in a competitor or blog.
Resources: include design, build, test, analysis time. Always round up.
For example, I usually estimate in weeks, rounding up: 1 hour of design, 2 days of PM time, 2 days of engineering, and 4 weeks waiting for A/B results = 1 + 1 + 1 + 4 = 7 weeks.
Final Thoughts
A/B tests don’t make decisions for you. They reduce the risk you’re making the wrong one.
And they’re always expensive. Not just to run, but in the opportunity cost of holding back good ideas.
The question isn’t should you test. It’s why you’re testing. And how you’re using what you learn.
Don’t outsource your judgment to a p-value.
Share this with someone who’s about to set up “just one more quick A/B test.”
Note: This article includes AI-generated images inspired by the authors of the Woke Salaryman Blog, feel free to subscribe.

.